Launch Week #2 Day 1: New Evaluation Dashboard
Launch Week #2 Day 1: New Evaluation Dashboard
Launch Week Day 1: Redesigned evaluation dashboard with side-by-side comparison, detailed debugging, and customizable LLM-as-a-judge evaluators.
Launch Week Day 1: Redesigned evaluation dashboard with side-by-side comparison, detailed debugging, and customizable LLM-as-a-judge evaluators.
Nov 10, 2025
Nov 10, 2025
-
5 minutes
5 minutes

Ship reliable AI apps faster
Agenta is the open-source LLMOps platform: prompt management, evals, and LLM observability all in one place.
Building reliable LLM apps is hard.
You change a prompt to fix one input. It looks better. Then you discover it broke something else.
Most teams spend months going in circles. They make changes but have no way to measure if they're actually improving.
Evals solve this. They give you a measurable way to improve prompts and workflows systematically.
That's why we spent months rebuilding evaluations from the ground up.
Evaluation Dashboard
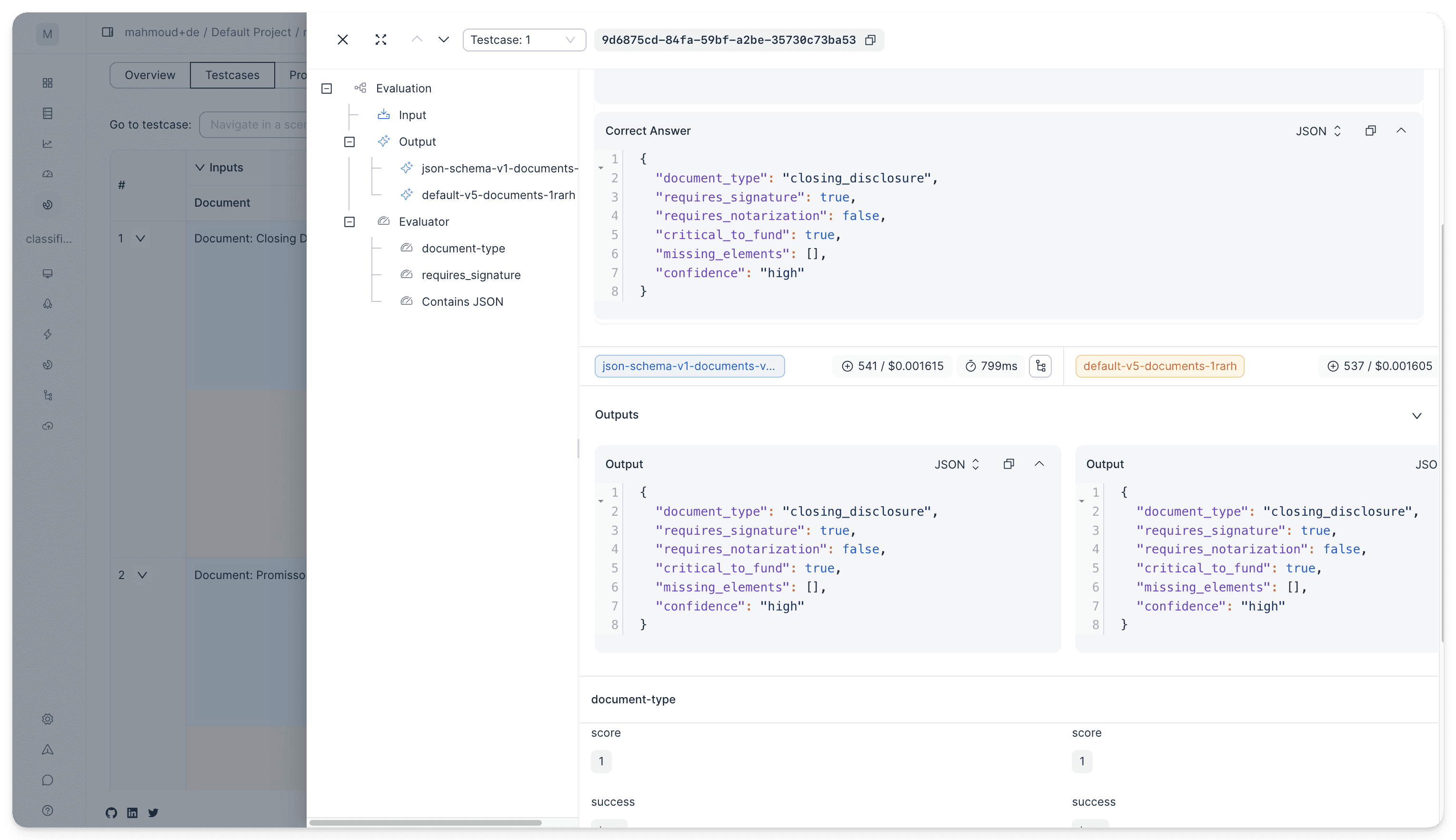
We redesigned the evaluation dashboard to give you a clear view of your prompts' performance.
The new dashboard lets you:
Get a quick overview. See how your prompts score across different metrics at a glance. No more digging through results to understand performance.
Dive into details. Jump into individual test cases and view results clearly. See the full input, output, and evaluation scores in one place.
Debug with traces. View the complete traces used to generate each output. Understand exactly what happened and why.
Catch regressions fast. Compare prompt versions side by side. See how changes affect results across all your test cases. Spot regressions before they reach production.
Keep context. View overview results, detailed results, and prompt configuration in one place. No more context switching between multiple tabs.
Evaluator Configuration
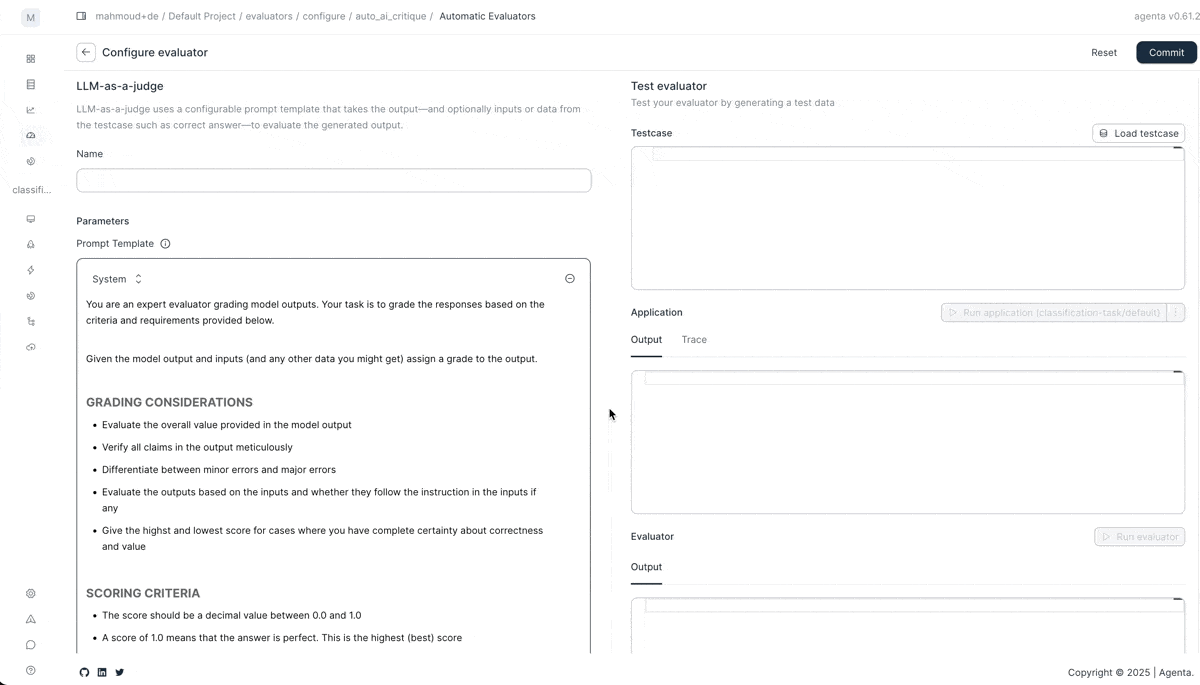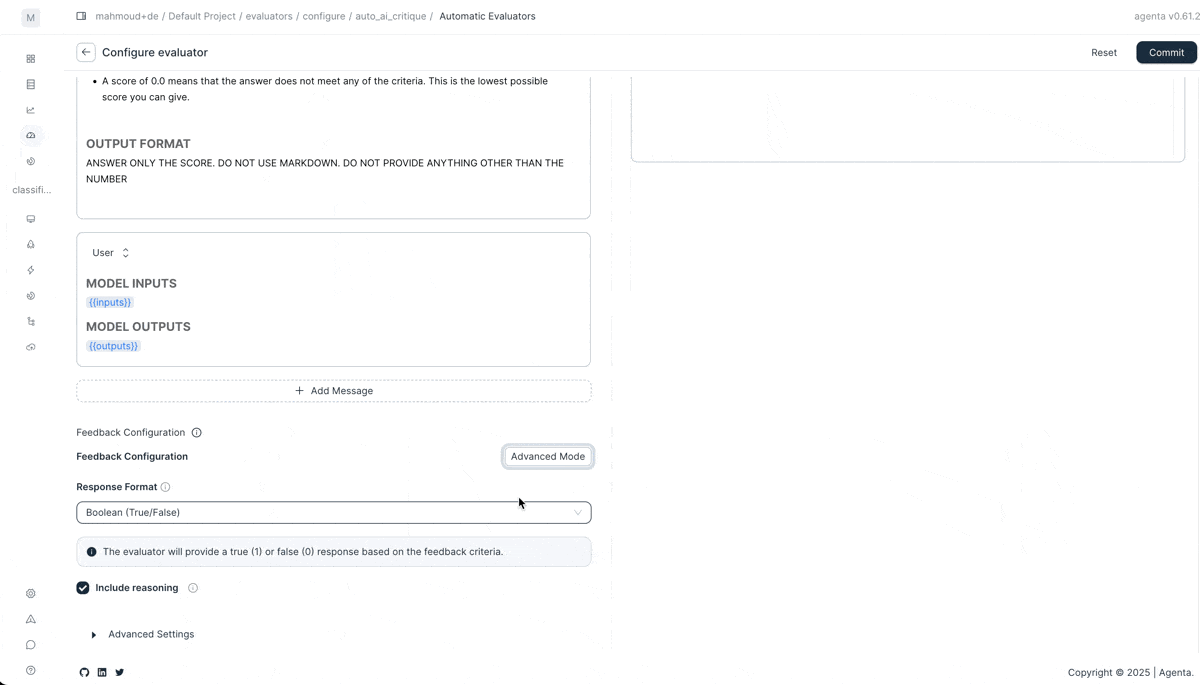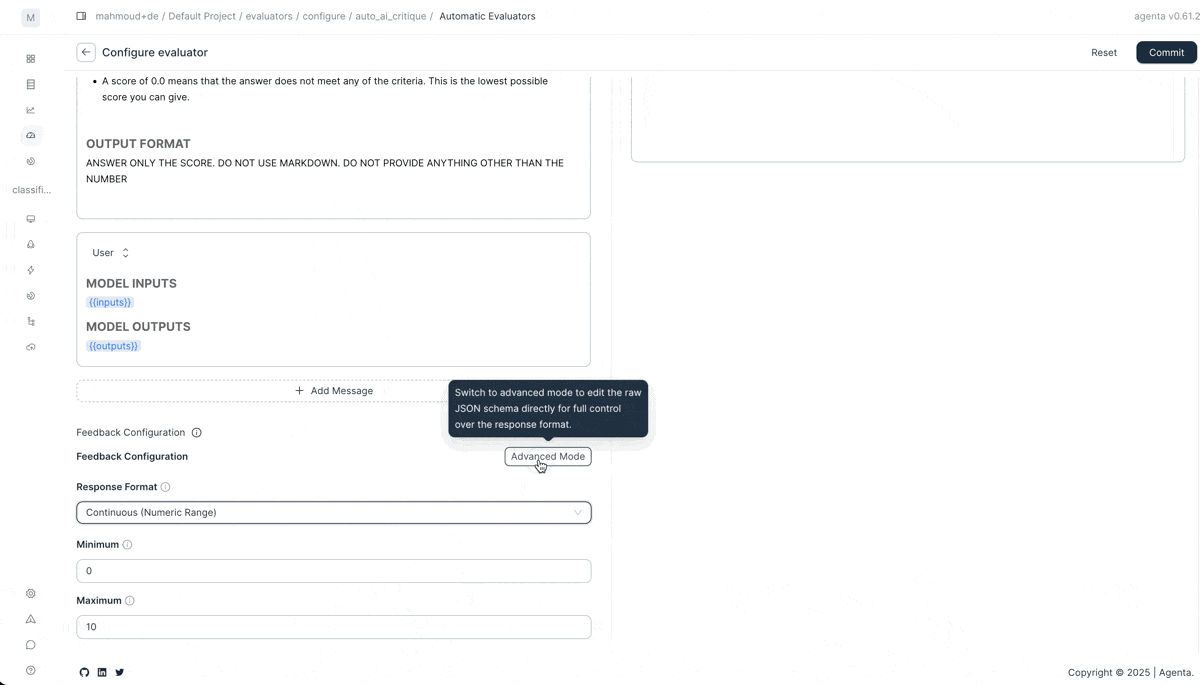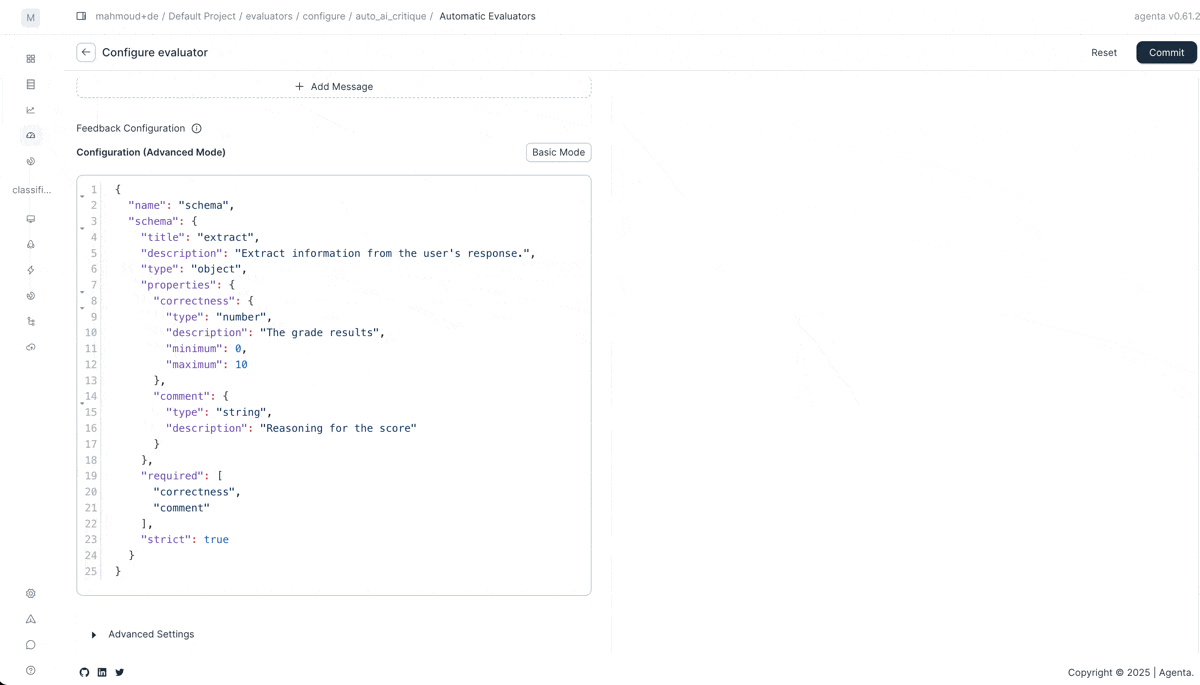
We also improved how you configure and test evaluators.
Test before you run. Use the improved evaluator playground to configure and test any built-in evaluator with real data. See how LLM-as-a-judge or code evaluators perform before running a full evaluation.
Browse all evaluators. The new evaluator registry shows all available evaluators in one place. Both automatic evaluators and human evaluation workflows.
Customize LLM-as-a-judge. Create multiple feedback outputs per evaluator with custom schemas. Return a binary score plus detailed reasoning. Or any structure you need. The LLM-as-a-judge evaluator now supports any output schema you define.
Get Started
Ready to try the new evaluation workflow?
Start evaluating in Agenta Cloud →
This is day 1 of our launch week. Check back tomorrow for the next announcement.
Building reliable LLM apps is hard.
You change a prompt to fix one input. It looks better. Then you discover it broke something else.
Most teams spend months going in circles. They make changes but have no way to measure if they're actually improving.
Evals solve this. They give you a measurable way to improve prompts and workflows systematically.
That's why we spent months rebuilding evaluations from the ground up.
Evaluation Dashboard
We redesigned the evaluation dashboard to give you a clear view of your prompts' performance.
The new dashboard lets you:
Get a quick overview. See how your prompts score across different metrics at a glance. No more digging through results to understand performance.
Dive into details. Jump into individual test cases and view results clearly. See the full input, output, and evaluation scores in one place.
Debug with traces. View the complete traces used to generate each output. Understand exactly what happened and why.
Catch regressions fast. Compare prompt versions side by side. See how changes affect results across all your test cases. Spot regressions before they reach production.
Keep context. View overview results, detailed results, and prompt configuration in one place. No more context switching between multiple tabs.
Evaluator Configuration
We also improved how you configure and test evaluators.
Test before you run. Use the improved evaluator playground to configure and test any built-in evaluator with real data. See how LLM-as-a-judge or code evaluators perform before running a full evaluation.
Browse all evaluators. The new evaluator registry shows all available evaluators in one place. Both automatic evaluators and human evaluation workflows.
Customize LLM-as-a-judge. Create multiple feedback outputs per evaluator with custom schemas. Return a binary score plus detailed reasoning. Or any structure you need. The LLM-as-a-judge evaluator now supports any output schema you define.
Get Started
Ready to try the new evaluation workflow?
Start evaluating in Agenta Cloud →
This is day 1 of our launch week. Check back tomorrow for the next announcement.

Co-Founder Agenta & LLM Engineering Expert
More from the Blog
More from the Blog
The latest updates and insights from Agenta
The latest updates and insights from Agenta




Ship reliable agents faster with Agenta
Build reliable LLM apps together with integrated prompt
management, evaluation, and observability.

Ship reliable agents faster with Agenta
Build reliable LLM apps together with integrated prompt
management, evaluation, and observability.
Ship reliable agents faster with Agenta
Build reliable LLM apps together with integrated prompt
management, evaluation, and observability.
Copyright © 2020 - 2060 Agentatech UG
Copyright © 2020 - 2060 Agentatech UG
Copyright © 2020 - 2060 Agentatech UG