
Introduction
As Retrieval-Augmented Generation (RAG) systems continue to shape the future of intelligent applications, one foundational step stands out: chunking.
The process of breaking down unstructured text into digestible, retrievable pieces. The way you chunk your documents directly impacts the quality of retrieval and, consequently, the relevance of your LLM’s responses.
Despite its importance, many teams settle for a single chunking strategy without exploring the nuances and trade-offs of alternative methods. But what if the performance of your entire RAG pipeline hinges on choosing the right one?
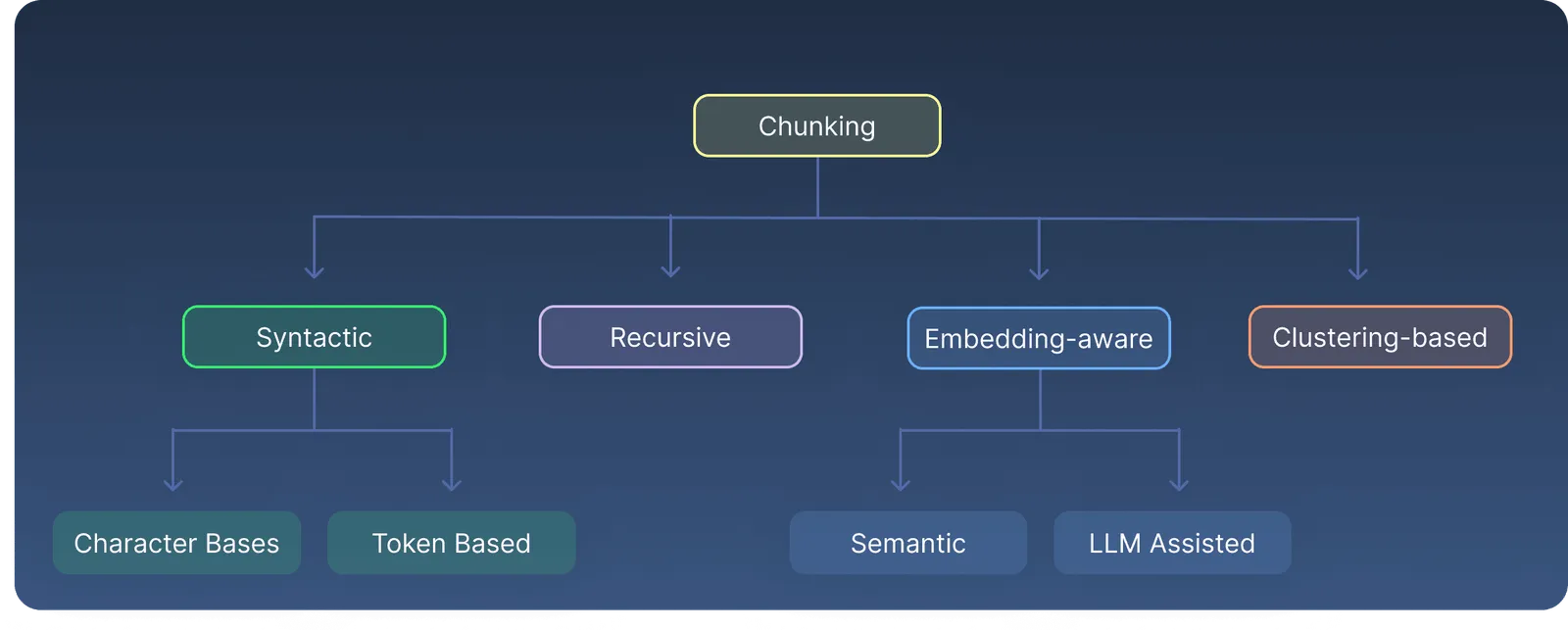
We’ll unpack four core approaches : syntactic, recursive, semantic, and cluster‑based, and show you how to put each one into practice. Let’s dive in.
Since this article includes code snippets for each method, we first start by importing the necessary libraries and initializing our chunkers :
# Main Chunking Functions
!pip install git+https://github.com/brandonstarxel/chunking_evaluation.git
from chunking_evaluation.chunkingimport (
ClusterSemanticChunker,
LLMSemanticChunker,
FixedTokenChunker,
RecursiveTokenChunker,
KamradtModifiedChunker
)
# Additional Dependenciesimport tiktoken
from chromadb.utilsimport embedding_functions
from chunking_evaluation.utilsimport openai_token_count
import osSyntactic chunking
Character-based chunking:
The most basic form of document chunking involves splitting text into fixed-length segments based on a predefined number of characters (e.g., every 100 characters). This method is appealing because it’s fast, language-agnostic, and easy to implement requiring no natural language processing or special tooling.
However, this simplicity comes at a cost. Fixed-character chunking does not account for the structure or meaning of the text. It can arbitrarily split:
- Sentences in the middle
- Paragraphs across chunks
- Named entities or key phrases, reducing coherence
For example, one chunk might end with:
“AGENTA platform supports prompt engineering, evaluation, and human anno”
and the next chunk starts with:
“tation workflows across multi-model deployments.”
To implement this chunking strategy Let us define a text to test on:
doc="""Agenta is an innovative open-source platform crafted to simplify and accelerate
the entire lifecycle of large language model (LLM) applications. It offers comprehensive
tools that cover every critical phase—from prompt engineering and fine-tuning to rigorous
evaluation and seamless deployment. At its core, Agenta supports version control for
prompts, allowing developers to experiment with and compare multiple prompt variants
side-by-side, thereby identifying the most effective approaches efficiently. Moreover,
it integrates built-in workflows for human feedback and annotation, empowering teams to
iteratively refine prompts and models based on real-world interactions and user input.
Agenta’s deployment features ensure smooth and scalable integration of LLM applications
into production environments, enabling businesses to deliver AI-driven solutions reliably
. To complement this, the platform includes robust observability and monitoring tools
that provide detailed insights into model performance metrics, user behavior, and error
cases—all consolidated into a single, intuitive dashboard. This end-to-end capability
makes Agenta a powerful ally for AI teams looking to build, optimize, and maintain
high-quality language model services with greater agility and transparency."""To better understand how chunking affects our data, we define an analyze_chunks function that prints out chunk counts and inspects overlaps between consecutive chunks both at the character and token level. These components will be fundamental throughout the rest of this guide as we experiment with and compare different chunking approaches.
def analyze_chunks(chunks, use_tokens=False):
print("\\nNumber of Chunks:", len(chunks))
if len(chunks) < 2:
print("Not enough chunks to analyze overlaps.")
return
# Pick the middle pair of chunks (or just the last two if fewer than 200)
idx1 = max(0, len(chunks) // 2 - 1)
idx2 = idx1 + 1
print("\\n", "="*50, f"Chunk {idx1}", "="*50, "\\n", chunks[idx1])
print("\\n", "="*50, f"Chunk {idx2}", "="*50, "\\n", chunks[idx2])
chunk1, chunk2 = chunks[idx1], chunks[idx2]
if use_tokens:
encoding = tiktoken.get_encoding("cl100k_base")
tokens1 = encoding.encode(chunk1)
tokens2 = encoding.encode(chunk2)
for i in range(len(tokens1), 0, -1):
if tokens1[-i:] == tokens2[:i]:
overlap = encoding.decode(tokens1[-i:])
print("\\nOverlapping text ({} tokens):\\n{}".format(i, overlap))
return
print("\\nNo token overlap found.")
else:
for i in range(min(len(chunk1), len(chunk2)), 0, -1):
if chunk1[-i:] == chunk2[:i]:
print("\\nOverlapping text ({} chars):\\n{}".format(i, chunk1[-i:]))
return
print("\\nNo character overlap found.")The following snippet of code implements the Character level chunking in python :
def chunk_text(document, chunk_size, overlap):
chunks = []
stride = chunk_size - overlap
current_idx = 0
while current_idx < len(document):
# Take chunk_size characters starting from current_idx
chunk = document[current_idx:current_idx + chunk_size]
if not chunk: # Break if we're out of text
break
chunks.append(chunk)
current_idx += stride # Move forward by stride
return chunks
character_chunks = chunk_text(doc, chunk_size=100, overlap=0)
analyze_chunks(character_chunks)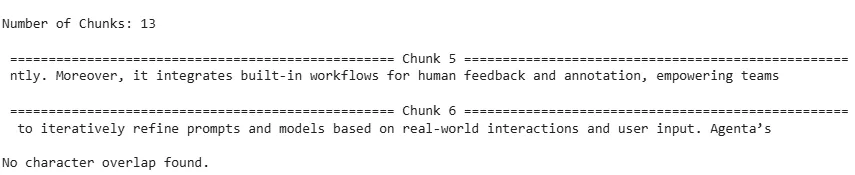
In this example, the document was split into 13 chunks of 100 characters each without any overlap. As a result, consecutive chunks such as Chunk 5 and Chunk 6 share no text, causing sentences and ideas to be split abruptly across chunk boundaries. This lack of overlap can lead to loss of important context, which may reduce the effectiveness of retrieval systems relying on these chunks since relevant information might be divided between separate pieces.
Such artificial breaks disrupt the semantic flow and make it harder for retrieval systems to return accurate and contextually complete answers, especially in use cases like Retrieval-Augmented Generation (RAG), where users might ask, “What services doesAgentaoffer for model evaluation and deployment?”
To mitigate this issue, overlapping chunks such as using 200-character chunks with 100-character overlap are often employed to maintain continuity between chunks. While overlap helps reduce fragmentation, it also introduces redundancy and increases the total number of chunks stored in your vector database.
Using the same chunk_text method, you can implement overlap by specifying how many characters should be shared between consecutive chunks. As expected, introducing overlap increases the total number of chunks generated.
character_chunks = chunk_text(doc, chunk_size=100, overlap=20)
analyze_chunks(character_chunks)
In short, fixed-character chunking is a good starting point but it’s rarely optimal when clarity, meaning, and structured responses are important.
Token based chunking:
Token-based chunking splits text into chunks based on a fixed number of tokens rather than characters. Unlike characters, tokens are language-aware units usually words or meaningful sub-words created by tokenizers used in modern language models like GPT. This approach aligns better with how models process text, as tokens represent the atomic pieces that the model “sees.”
An example of tokenization for the text specified earlier in the article is shown here where each colour represents a different token using the OpenAI’s tokenizer :

Using token counts for chunking has several advantages:
- Consistent size for model input: Language models typically have token limits, so chunking by tokens helps ensure chunks fit within those limits without accidentally cutting words in half.
- Better preservation of meaning: Since tokens roughly correspond to words or subwords, token-based chunks tend to avoid splitting inside words or important phrases, reducing semantic fragmentation.
- Language model compatibility: Because tokenizers are model-specific (e.g., OpenAI’s
tiktoken), token-based chunking matches exactly what the model will process, avoiding mismatches in length estimation.
One way to implement token-based chunking is through the use of thetiktokenLibrary,
import tiktoken
# Loading cl100k_base tokenizer
encoder = tiktoken.get_encoding("cl100k_base")
def count_tokens(text, model="cl100k_base"):
"""Count tokens in a text string using tiktoken"""
encoder = tiktoken.get_encoding(model)
return print(f"Number of tokens: {len(encoder.encode(text))}")
fixed_token_chunker = FixedTokenChunker(
chunk_size=100,
chunk_overlap=0,
encoding_name="cl100k_base"
)
token_chunks = fixed_token_chunker.split_text(doc)
analyze_chunks(token_chunks, use_tokens=True)This code begins by loading the "cl100k_base" tokenizer to encode text into tokens. A FixedTokenChunker is then configured to split the input document into chunks of 100 tokens each, without overlap.

To activate overlapping, all you have to do is to specify the chunk_overlap parameter value to something more than zero.
fixed_token_chunker = FixedTokenChunker(
chunk_size=100,
chunk_overlap=20,
encoding_name="cl100k_base"
)
token_overlap_chunks = fixed_token_chunker.split_text(doc)
analyze_chunks(token_overlap_chunks, use_tokens=True)
Recursive chunking
Recursive Chunking is a technique that divides text by following a hierarchical list of natural separators. It begins by splitting the text at larger boundaries, such as double newlines representing paragraph breaks. If the resulting chunks still exceed the desired size, the method recursively breaks them down further using smaller separators like single newlines, sentence-ending punctuation, spaces, and finally individual characters if necessary. An illustration of the process is shown here :
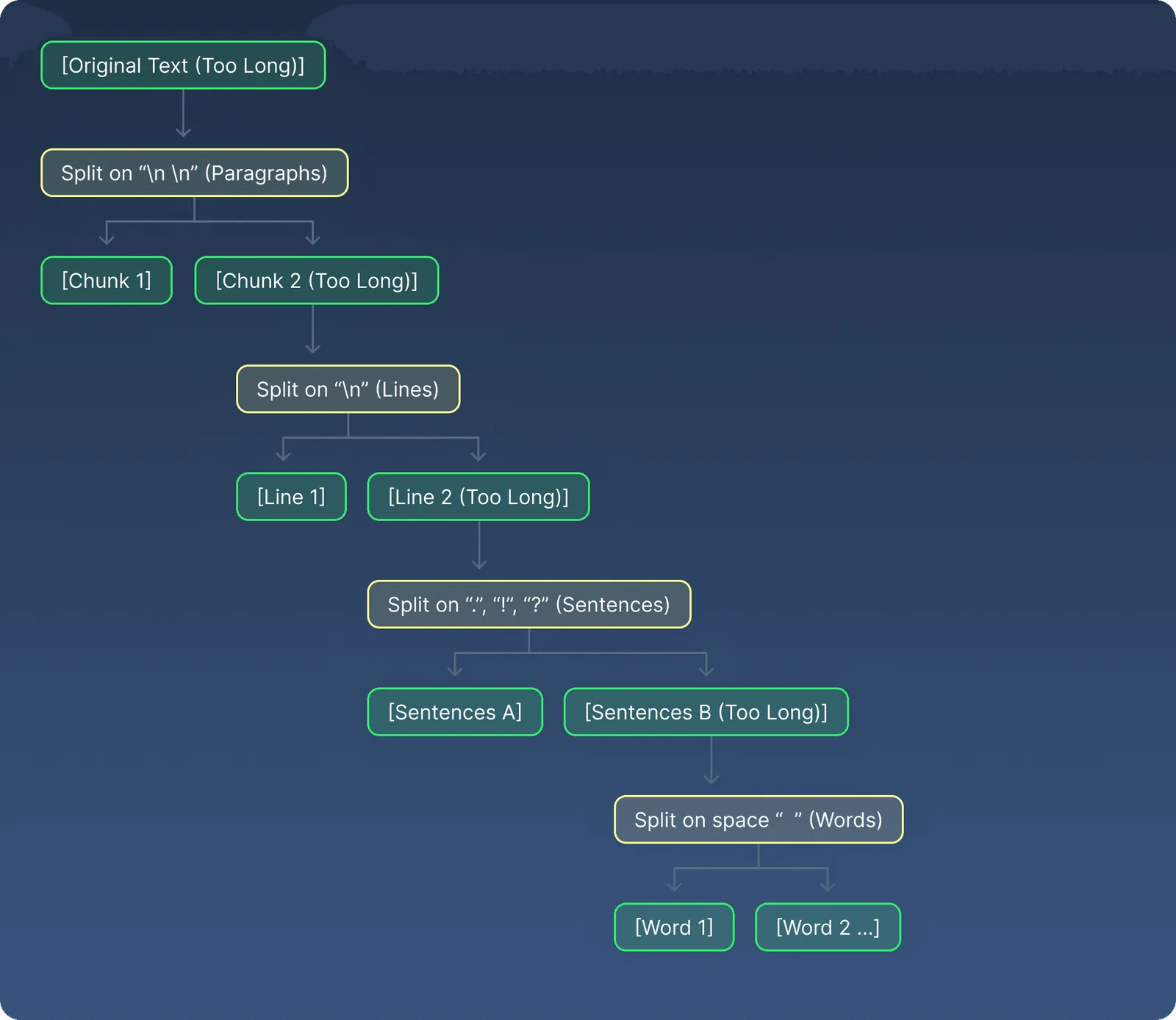
Counting tokens or characters cannot take us so fat in complex real world scenarios. When we write, our text naturally organizes itself into meaningful units such as paragraphs, sentences, and words. Recursive chunking leverages this inherent structure by intelligently splitting text based on progressively smaller natural separators, all while respecting a maximum chunk size limit.
The recursive character text splitter begins by scanning the entire document and first attempts to split it using paragraph breaks (\\n\\n). This initial pass creates a set of chunks that align well with the highest-level logical units of the text. However, some of these chunks may still be too large to fit within size constraints.
For any chunks exceeding the maximum allowed length, the splitter recursively processes them using smaller and smaller separators in a defined order. It first tries to break these large chunks on line breaks (\\n), which correspond to smaller sections than paragraphs. If the chunks remain too big, it next tries splitting on sentence boundaries marked by punctuation such as periods (.), question marks (?), or exclamation points (!). When sentences are still too long, it attempts to split on spaces between words. Finally, if no natural separator is sufficient to meet the chunk size requirement, the splitter falls back to dividing the text at the individual character level.
This recursive approach allows the splitter to preserve as much of the text’s natural structure as possible. Chunks that are already small enough remain untouched, maintaining their semantic coherence. Only those that are too large get progressively broken down into smaller pieces until they meet the size constraints. The result is a set of chunks that balance the need for manageable size with the preservation of meaningful text units, improving the quality of downstream tasks such as retrieval and language model input.
A possible implementation of this recursive chunking without overlapping is shown here where The chunker uses a hierarchy of separators, to preserve the natural structure of the text as much as possible, only resorting to smaller units when necessary to meet the size constraint :
recursive_character_chunker = RecursiveTokenChunker(
chunk_size=100, # Character Length
chunk_overlap=0, # Overlap
length_function=len, # Character length with len()
separators=["\\n\\n", "\\n", ".", "?", "!", " ", ""]
)
recursive_character_chunks = recursive_character_chunker.split_text(doc)
analyze_chunks(recursive_character_chunks, use_tokens=False)
Now we set chunk_overlap=20 , which means that each chunk will share 20 characters with the previous one. This is useful when some context from the previous chunk is needed to understand the next one (which is often the case in language modeling or information retrieval).
recursive_character_chunker = RecursiveTokenChunker(
chunk_size=100, # Character Length
chunk_overlap=20, # Overlap
length_function=len,
separators=["\\n\\n", "\\n", ".", "?", "!", " ", ""]
)
recursive_character_overlap_chunks = recursive_character_chunker.split_text(doc)
analyze_chunks(recursive_character_overlap_chunks, use_tokens=False)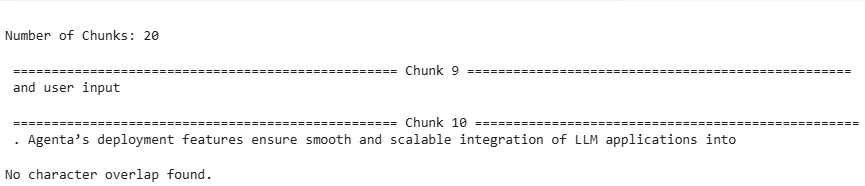
Semantic chunking
Traditional text chunking methods like fixed character windows, sentence-level, or paragraph-based splitting suffer from a simple yet significant limitation: they break text without understanding its meaning. This can result in unnatural fragmentations where ideas are split mid-thought or chunks vary wildly in informativeness. This is where semantic chunking ****comes in.
Semantic Chunking is an advanced technique that uses text embeddings to split documents based on their semantic content instead of arbitrary positions or formatting cues. Rather than slicing at fixed intervals, the algorithm looks for meaningful transitions in content and tries to preserve cohesive ideas within each chunk. The goal is to produce chunks that make more sense for downstream tasks like retrieval, summarization, or question answering.
Imagine reading a novel and trying to summarize it paragraph by paragraph. Some paragraphs may have deep, context-rich content while others serve as transitions or contain only one short sentence. Semantic chunking takes this imbalance into account and restructures text into more meaningful blocks.
One popular implementation comes from Greg Kamradt’s “5 Levels of Text Splitting”, later improved by the team at Chroma and adopted into tools like LangChain. Here’s the process at a high level:
- Embedding the Text: This is the first and foundational step in semantic chunking. The goal here is to transform the raw text into numerical representations that capture meaning and context. We begin by splitting the text into small candidate windows typically individual sentences or pairs of sentences. These are not yet final chunks, but small enough units that still carry meaningful context. Each of these windows is then passed through a text embedding model (e.g., OpenAI’s
text-embedding-3-large), which converts them into dense vectors in a high-dimensional space. These vectors represent the semantic meaning of the text, not just the words themselves. - Measuring Semantic Distances: Once each sentence or segment is transformed into an embedding vector, the algorithm measures the semantic similarity between adjacent vectors using cosine similarity. An example is shown here : Let’s say we used an embedding model (like OpenAI’s
text-embedding-3-large) to convert two sentences into the following vectors: A =[0.1, -0.4, 0.3]→ (e.g., “The dog barked.”) B =[0.09, -0.41, 0.29]→ (e.g., “It was late at night.”) To check how similar these two sentences are in meaning, we use cosine similarity:
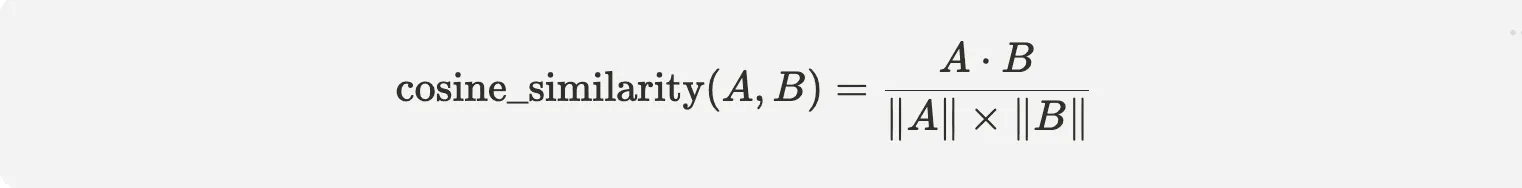
We start by computing the dot product:
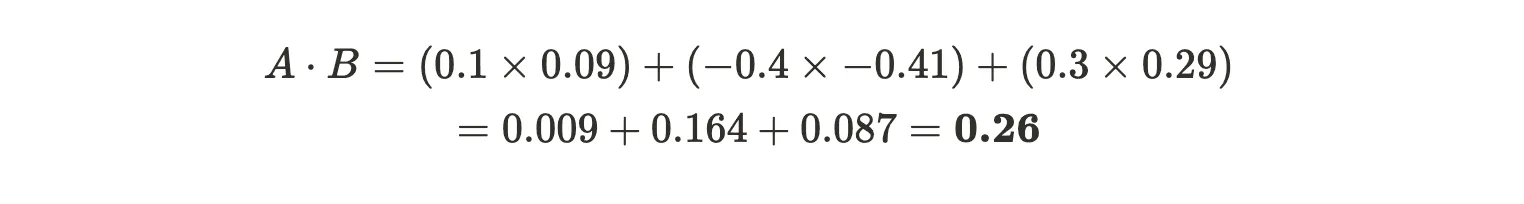
Then we compute the magnitudes
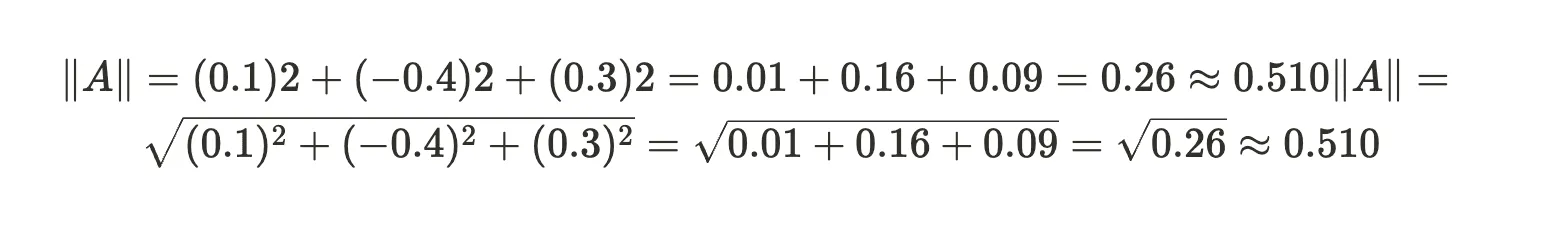
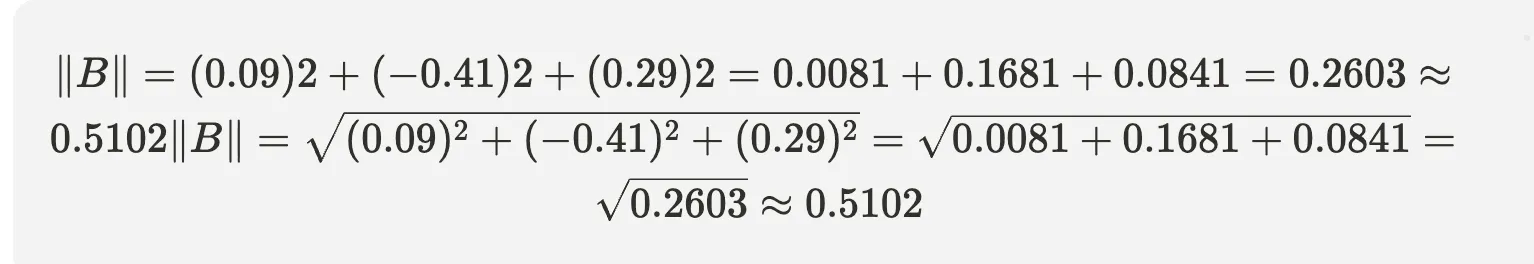
And finally the Cosine similarity
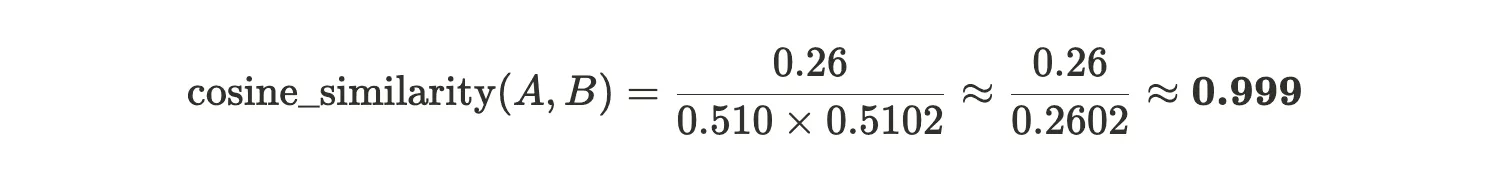
A score of ~0.999 means these sentences are extremely close in meaning therefore no chunk boundary needed here.
- Optimizing Chunk Size:
To find the largest chunk size that fits within token limits while keeping the text semantically coherent, binary search is used to test different group sizes. For instance, imagine you have five sentences about weather and finance (S1, S2, S3, S4, S5). Each sentence is converted into an embedding vector, and cosine similarity is calculated between adjacent sentences to measure their relatedness.
S1=[0.1, 0.3, 0.5]
S2=[0.15, 0.35, 0.45]
S3=[0.8, 0.7, 0.1]
S4=[0.75, 0.65, 0.2]
S5=[0.12, 0.33, 0.48]
Starting with a guess, such as grouping three sentences, you check if they are all semantically similar. You find these results :
[ S1 ]──(high)<strong>──[ S2 ]──</strong>(low)<strong>──[ S3 ]──</strong>(high)<strong>──[ S4 ]──</strong>(low)──[ S5 ]
Sentences 1 to 3 don’t group well because the similarity between sentence 2 and 3 is low, so the chunk breaks topic coherence.
Chunk size=3: [S1 S2 S3] ✗ (low similarity 2-3)
Next, testing a chunk size of two works better, grouping sentences 1 and 2 together and 3 and 4 together, both with high similarity.
Chunk size=2: [S1 S2] ✓ [S3 S4] ✓
Trying a chunk size of four again fails due to topic mismatch.
Chunk size=4: [S1 S2 S3 S4] ✗
After determining which groups are semantically coherent, each chunk’s total tokens are checked to ensure they don’t exceed limits. If a chunk is too large, binary search reduces the size and repeats this process until the optimal chunk size balances semantic similarity and token constraints. As a result to this process we get a list of semantically meaningful chunks.
A full example of code is shown here on how to use OpenAi’s embedding model to implement semantic chunking on the Pride and Prejudice by Jane Austen | Project Gutenberg book of 476 pages of text, or 175,651 tokens :
# 1. Import the helper function for OpenAI embeddings
embedding_function = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-3-large"
)
# 2. Import LangChain's SemanticChunker
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# 3. Instantiate the chunker using OpenAI embeddings
lc_semantic_chunker = SemanticChunker(OpenAIEmbeddings())
# 4. Apply the chunker to your document
lc_semantic_chunks = lc_semantic_chunker.create_documents([document])
# 5. Inspect number of generated chunks and some examples
print("# of Chunks:", len(lc_semantic_chunks), "\\n")
print(lc_semantic_chunks[199].page_content)
print("\\n\\n", "="*50, "\\n\\n")
print(lc_semantic_chunks[200].page_content)
print("\\n\\n", "="*50, "\\n\\n")
# 6. Optional: Count tokens in each chunk
count_tokens(lc_semantic_chunks[199].page_content)
count_tokens(lc_semantic_chunks[200].page_content)Chunk 199 :

Chunk 200:

Token counting ensures that each chunk remains within the context window limits of the language model being used, such as 512 or 1000 tokens. In our example, we printed the tokens in chunks 199 and 200.

Chunk 199 contains 577 tokens and chunk 200 has 511 tokens both well within reasonable bounds for efficient processing. Importantly, these chunks are not just arbitrarily sized; they are semantically coherent. Chunk 199 captures a smooth narrative flow from a character’s question to emotional distress and eventual departure preserving both dialogue and plot progression. Chunk 200, on the other hand, encapsulates a reflective conversation among characters about morality and intentions, maintaining thematic unity throughout. This shows how semantic chunking respects the natural structure of the text, producing segments that are both meaningful and optimized for language model input.
LLM-assisted semantic chunking
While most chunking strategies rely on embeddings or heuristics to determine where to split a document, LLM Semantic Chunking takes a radically different and surprisingly simple approach:
** It asks the language model directly: “Where should I split this text?”**This method uses the full reasoning capabilities of an LLM to determine semantic boundaries between ideas, paragraphs, or narrative scenes. Instead of relying on similarity scores, the LLM uses its understanding of discourse and structure to intelligently group text into thematically consistent blocks. Here’s a breakdown of the process:
The input document is first broken into small, manageable pieces using a simple recursive character-based splitter. Each of these mini-chunks is then wrapped with unique tags for identification:
plaintext
CopyEdit
<|start_chunk_1|> Text here... <|end_chunk_1|>
<|start_chunk_2|> More text... <|end_chunk_2|>These tags help the LLM refer to and reason about individual sections.
The chunker then processes the document in sliding windows, typically covering 10–16 of these 50-token mini-chunks at a time. This ensures the LLM works with a contextually rich, but manageable portion of the text.
For each window, a system prompt like the following is used:
You are an assistant trained to divide text into sections that are thematically consistent. The text is pre-split into small chunks, each enclosed between
<|start_chunk_X|>and<|end_chunk_X|>tags, whereXis the chunk number. Your task is to determine where natural breaks should occur identify the points at which the topic or theme shifts so that related chunks remain grouped together. Please return a list of chunk IDs after which a split should be made. For example, if chunks 1 and 2 belong to the same idea, but chunk 3 introduces a new one, you would respond with:split_after: 2
The model sees tagged chunks and is asked to suggest where semantic breaks should occur. For instance:
split_after: 2, 4This means: “Group chunks 1–2 together, then 3–4, then continue from chunk 5.”
After receiving a list of split points, the chunker moves the window forward, starting at the last suggested split. This ensures that every part of the document is eventually covered and grouped into semantic blocks.
The result? A new list of high-quality chunks, each consisting of multiple original mini-chunks intelligently grouped by the LLM based on meaning, tone, and structure.
One way to implement this LLM-assisted chunker is shown here :
llm_chunker = LLMSemanticChunker(
organisation="openai",
model_name="gpt-4o",
api_key=os.environ["OPENAI_API_KEY"])
llm_chunker_chunks = llm_chunker.split_text(doc)
analyze_chunks(llm_chunker_chunks, use_tokens=True)The chunk made by this LLM powered chunker using the defined system prompt is :
Cluster-based chunking
The ClusterSemanticChunker is an advanced method for splitting large text documents into semantically meaningful chunks. Unlike traditional approaches that make local or sequential decisions (like fixed-length splits or sliding windows), this chunker looks at the entire document globally to find the most coherent way to group related text. It does this by considering how all parts of the document relate to each other in meaning and then uses optimization techniques to form the best chunks possible, all while keeping chunk sizes within a practical limit.
An overview of the approach is shown here :
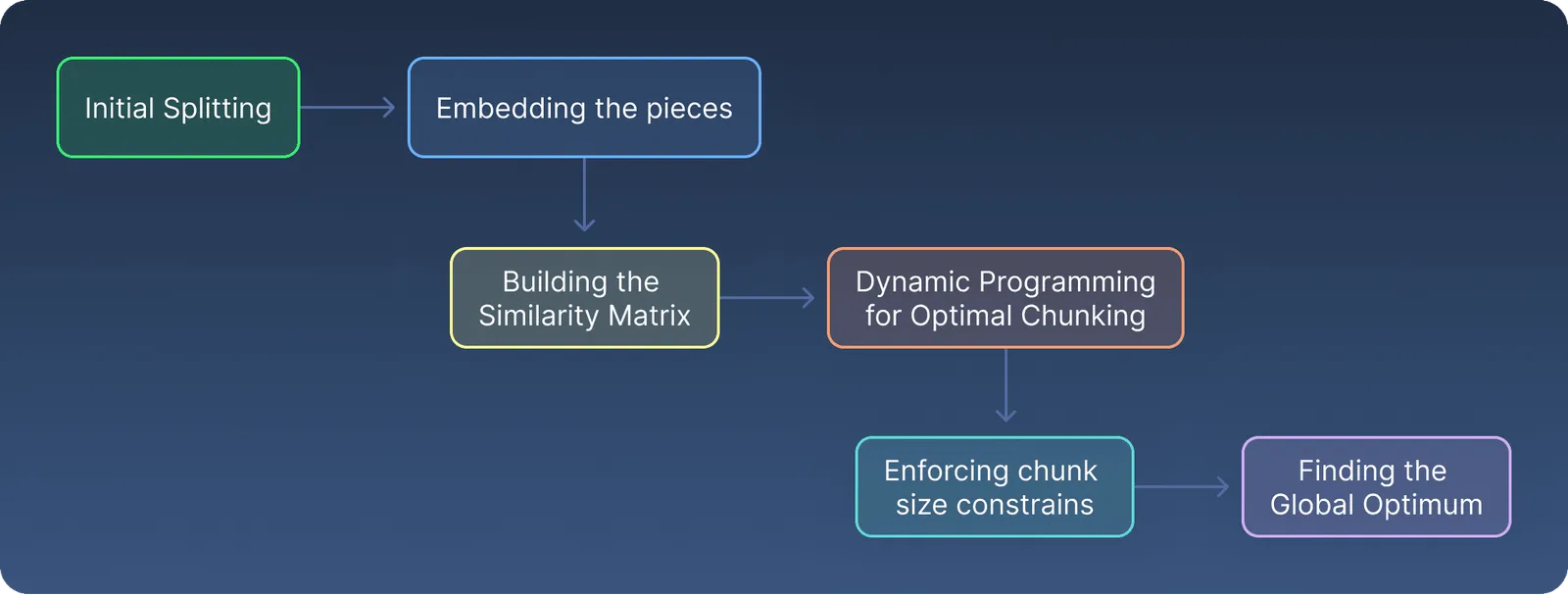
- Initial Splitting into Small Pieces The input text is first split into small, fixed-size segments (typically around 50 tokens). This ensures the input is manageable and that semantic patterns can be analyzed at a finer level.
- Embedding Each Piece Each small piece of text is transformed into a vector using a language model (i.e., it’s embedded). This vector represents the semantic meaning of the text fragment.
- Building a Similarity Matrix A similarity matrix is created by calculating cosine similarity between all pairs of embeddings. This matrix shows how semantically related each pair of text pieces is.
- Dynamic Programming Optimization Using dynamic programming, the chunker searches for the best way to group the small pieces into larger chunks. For each possible chunk, it calculates a semantic reward—a score representing how internally cohesive the group is.
- Applying Size Constraints It enforces a limit (
max_cluster) on how many pieces can be in one chunk. This ensures that the final chunks are not too large for downstream tasks like retrieval or LLM input. - Selecting the Best Chunking The algorithm selects the chunk configuration with the highest total semantic reward, giving you a set of text chunks that are both coherent and size-appropriate.
One way to implement it is using the : ClusterSemanticChunker
cluster_chunker = ClusterSemanticChunker(
embedding_function=embedding_function,
max_chunk_size=400,
length_function=openai_token_count
)
cluster_chunker_chunks = cluster_chunker.split_text(document)
analyze_chunks(cluster_chunker_chunks, use_tokens=True)
Evaluation
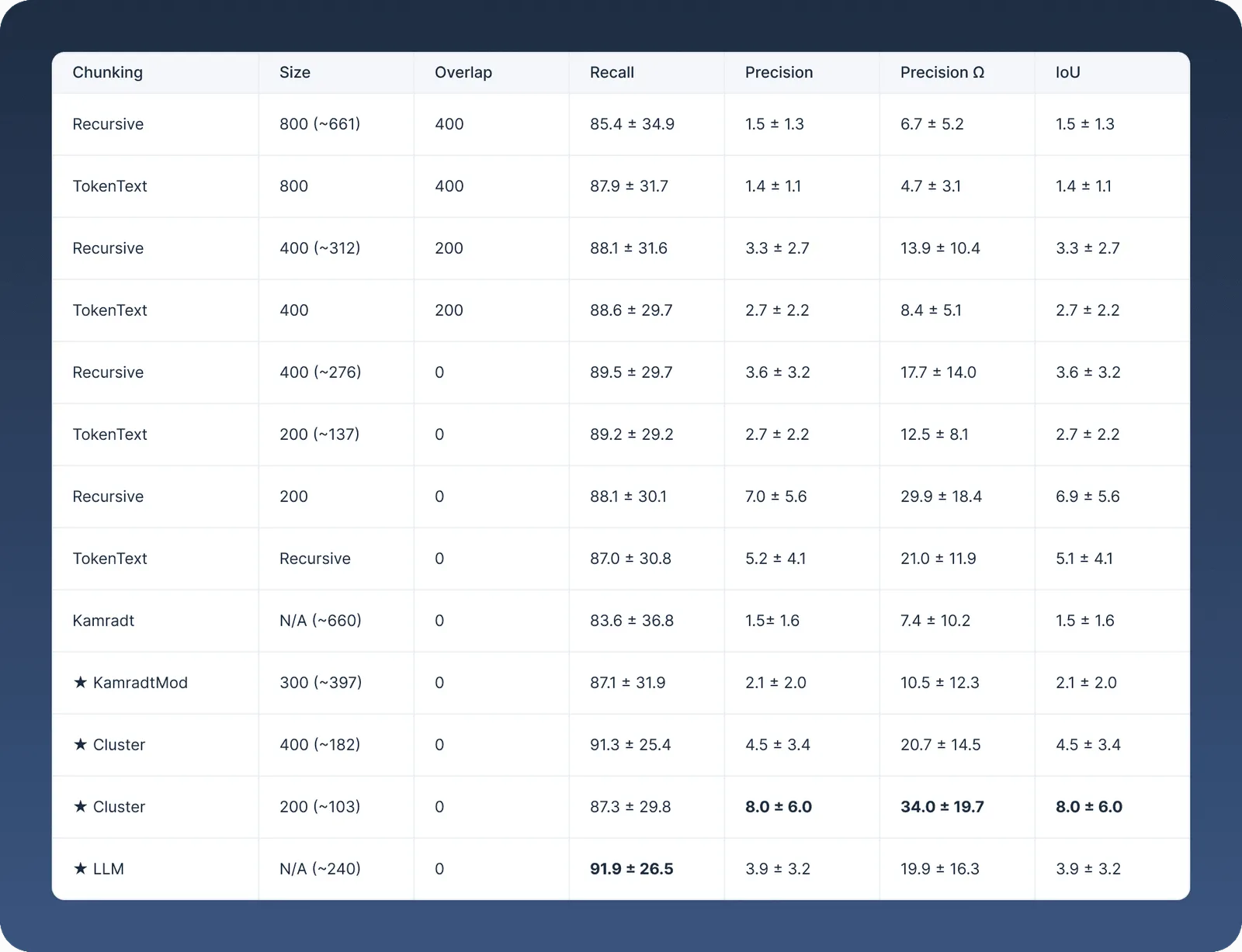
The Chroma Technical Report (July 3, 2024), titled “Evaluating Chunking Strategies for Retrieval”, assess the effectiveness of these different text chunking methods used in Retrieval-Augmented Generation (RAG) systems using metrics such as Recall, Precision, Precision Ω (maximum achievable precision under perfect recall), and IoU (Intersection over Union) which captures both completeness and efficiency by penalizing irrelevant token inclusion and missed relevant tokens.
The study found that ClusterSemanticChunker with 400 tokens achieved the second-highest recall (91.3%) and solid efficiency, while the same chunker at 200 tokens achieved the highest precision (8.0%), Precision Ω (34.0%), and IoU (8.0%). In contrast, LLMSemanticChunker had the highest recall (91.9%) but lower efficiency. Simpler methods like RecursiveCharacterTextSplitter (200 tokens, no overlap) performed consistently well across all metrics and even outperformed complex strategies like OpenAI’s default chunker (800 tokens, 400 overlap), which showed below-average results. Notably, reducing chunk overlap improved efficiency (IoU) by minimizing redundancy. Based on these findings, the report recommends either using RecursiveCharacterTextSplitter with 200–400 token chunks and no overlap for simplicity and good performance, or ClusterSemanticChunker for maximum efficiency if complexity is acceptable. The results are summarized in this table :
Building Production-Ready RAG Systems
Choosing the right chunking strategy is crucial for RAG system performance, but it’s just one optimization technique among many. For a complete guide to improving your RAG applications, check out our article on Top 10 Techniques to Improve RAG Applications.
The key to success is systematic evaluation: version all changes, evaluate each modification, and monitor results in production. For more insights on evaluation best practices, check out our blog post about evaluating RAG applications.
Ready to optimize your RAG system? Try Agenta—our open-source LLMOps platform that makes it easy to experiment with chunking strategies, test different prompts, and evaluate your entire RAG pipeline in one place.




