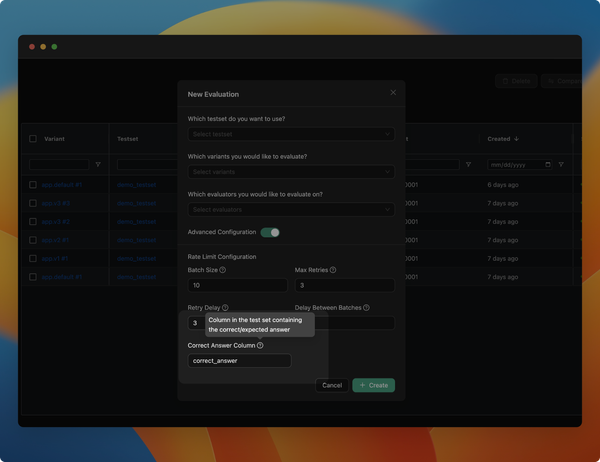
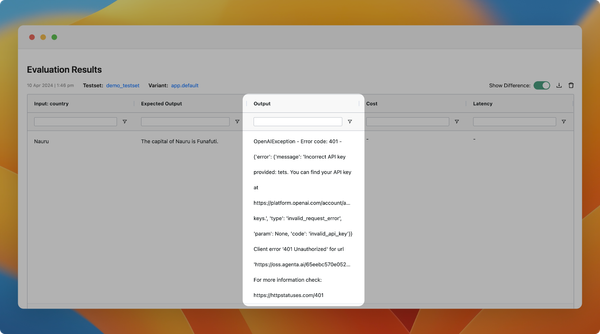
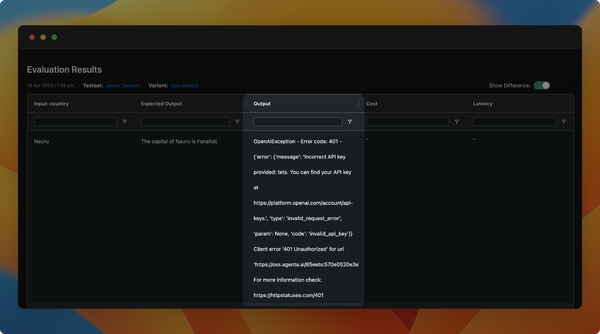
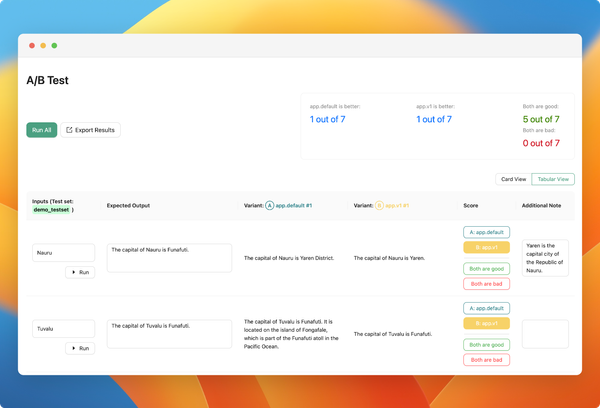
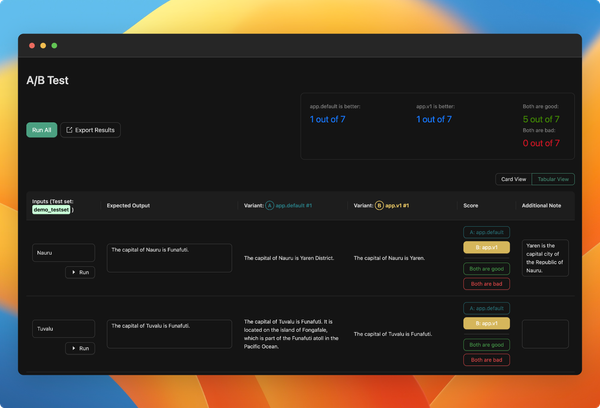
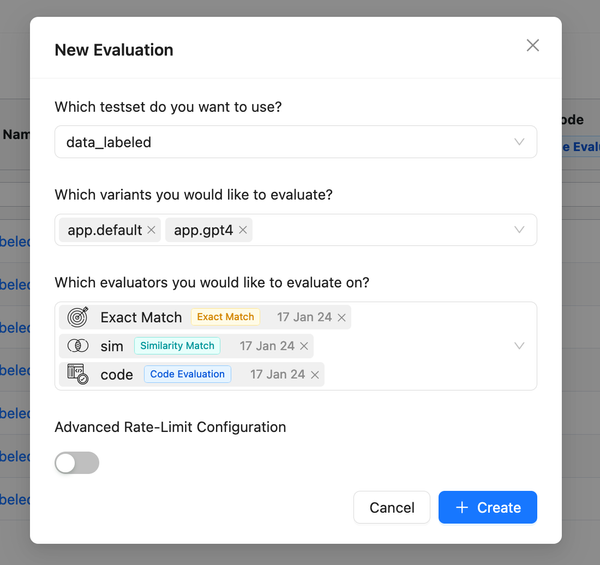
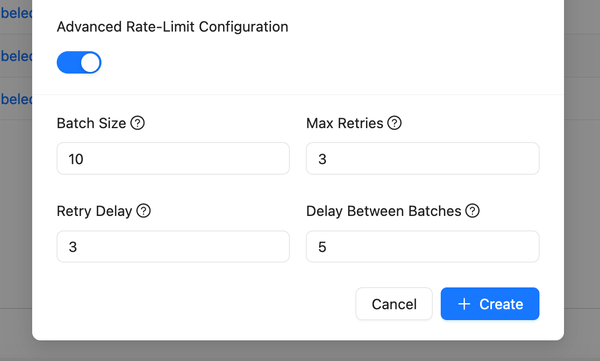
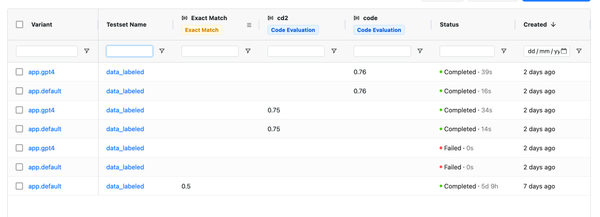
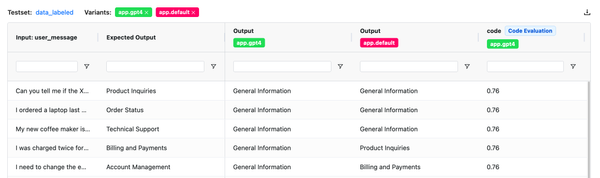
Highlight ouput difference when comparing evaluations
We have improved the evaluation comparison view to show the difference to the expected output.
Improvements
- Improved the error messages when invoking LLM applications
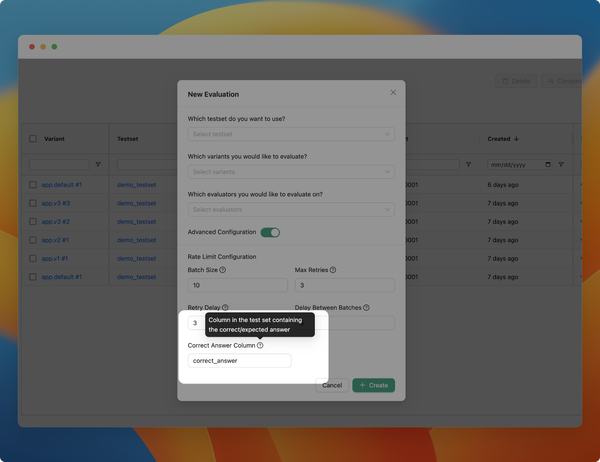
- Improved "Add new evaluation" modal
- Upgraded Sidemenu to display Configure evaluator and run evaluator under Evaluations section
- Changed cursor to pointer when hovering over evaluation results