Evaluation SDK
You can now run programmatic evaluations of complex AI agents and workflows directly from code. The Evaluation SDK gives you full control over test data and evaluation logic. It works with agents built using any framework.
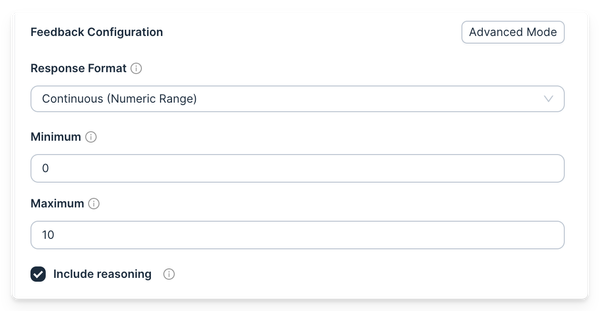
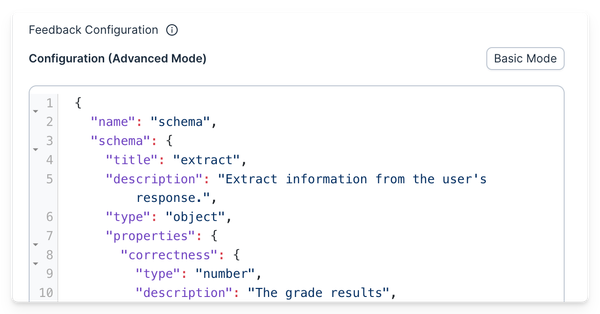
The SDK lets you create test sets in code or fetch them from Agenta. You can use built-in evaluators like LLM-as-a-Judge, semantic similarity, or regex matching. You can also write custom Python evaluators. The SDK evaluates end-to-end workflows or specific spans in execution traces. Evaluations run on your own infrastructure; results display in the Agenta dashboard.
Check out the Evaluation SDK documentation to get started.