We are SOC 2 Type 2 Certified
We are SOC 2 Type 2 Certified. This means that our platform is audited and certified by an independent third party to meet the highest standards of security and compliance.
New features, improvements, and fixes in Agenta.
We are SOC 2 Type 2 Certified. This means that our platform is audited and certified by an independent third party to meet the highest standards of security and compliance.
We now support structured output support in the playground. You can define the expected output format and validate the output against it.
With Agenta's playground, implementing structured outputs is straightforward:
Open any prompt
Switch the Response format dropdown from text to JSON mode or JSON Schema
Paste or write your schema (Agenta supports the full JSON Schema specification)
Run the prompt - the response panel will show the response beautified
Commit the changes - the schema will be saved with your prompt, so when your SDK fetches the prompt, it will include the schema information
Check out the blog post for more detail https://agenta.ai/blog/structured-outputs-playground
We've introduced the Prompt and Deployment Registry, giving you a centralized place to manage all variants and versions of your prompts and deployments.
Key capabilities:
Learn more in our blog post.
Bug Fixes
We've made several improvements to the playground, including:
As for custom workflows, now they work with sub-routes. This means you can have multiple routes in one file and create multiple custom workflows from the same file.
We've introduced major improvements to Agenta, focusing on OpenTelemetry compliance and simplified custom workflow debugging.
OpenTelemetry (OTel) Support:
Agenta is now fully OpenTelemetry-compliant. This means you can seamlessly integrate Agenta with thousands of OTel-compatible services using existing SDKs. To integrate your application with Agenta, simply configure an OTel exporter pointing to your Agenta endpoint—no additional setup required.
We've enhanced distributed tracing capabilities to better debug complex distributed agent systems. All HTTP interactions between agents—whether running within Agenta's SDK or externally—are automatically traced, making troubleshooting and monitoring easier.
Detailed instructions and examples are available in our distributed tracing documentation.
Improved Custom Workflows:
Based on your feedback, we've streamlined debugging and running custom workflows:
Run workflows from your environments: You no longer need the Agenta CLI to manage custom workflows. Setting up custom workflows now involves simply adding the Agenta SDK to your code, creating an endpoint, and connecting it to Agenta via the web UI. You can check how it's done in the quick start guide.
Custom Workflows in the new playground: Custom workflows are now fully compatible with the new playground. You can now nest configurations, run side-by-side comparisons, and debug your agents and complex workflows very easily.
We've rebuilt our playground from scratch to make prompt engineering faster and more intuitive. The old playground took 20 seconds to create a prompt - now it's instant.
Key improvements:
For developers, now you create prompts programmatically through our API.
You can explore these features in our updated playground documentation.
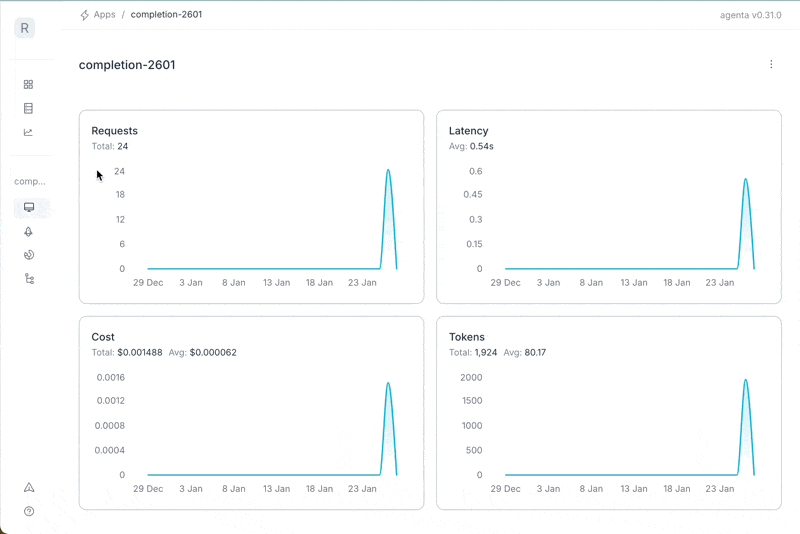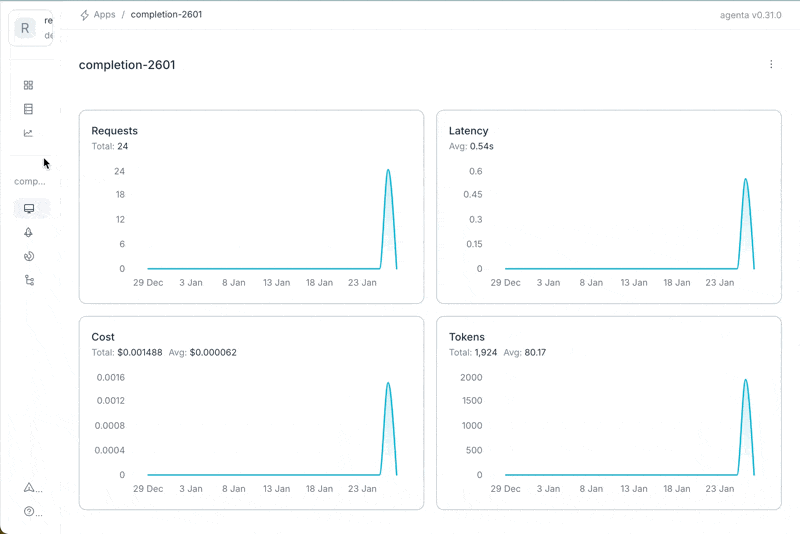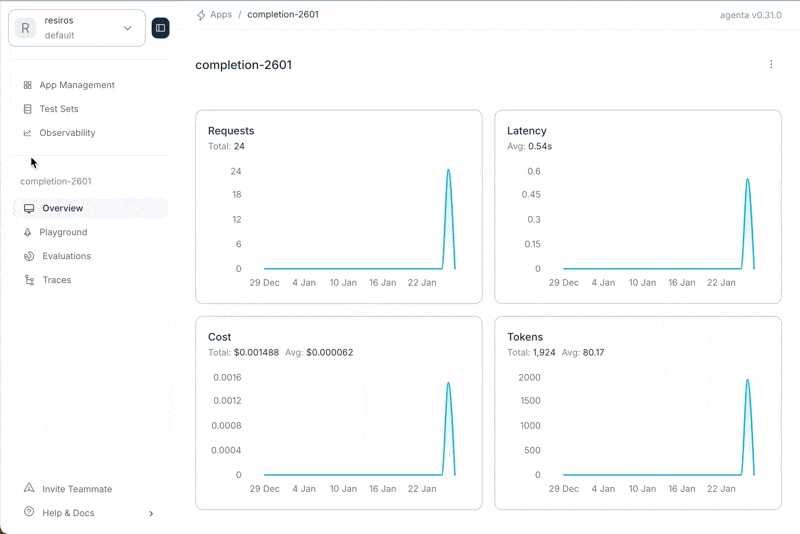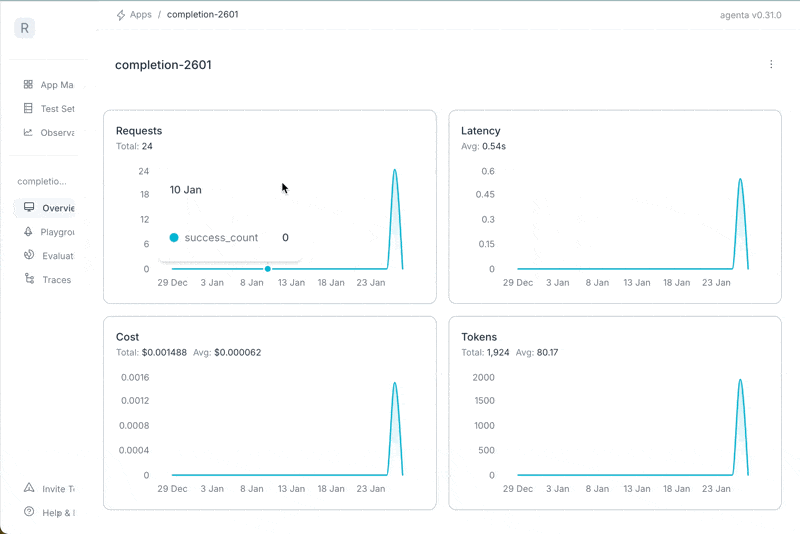
Small release today with quality of life improvements, while we're preparing the huge release coming up in the next days:

We've achieved SOC 2 Type 1 certification, validating our security controls for protecting sensitive LLM development data. This certification covers our entire platform, including prompt management, evaluation frameworks, and observability tools.
Key security features and improvements:
This certification represents a significant milestone for teams using Agenta in production environments. Whether you're using our open-source platform or cloud offering, you can now build LLM applications with enterprise-grade security confidence.
We've also updated our trust center with detailed information about our security practices and compliance standards. For teams interested in learning more about our security controls or requesting our SOC 2 report, please contact [email protected].

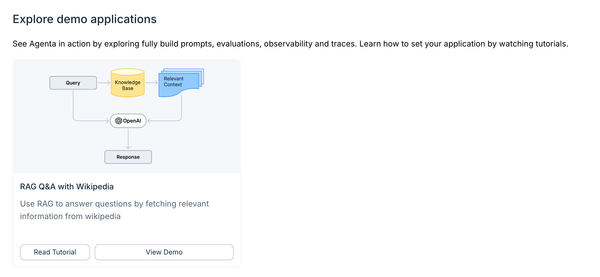
We've redesigned our platform's onboarding to make getting started simpler and more intuitive. Key improvements include:
This release introduces the ability to add spans to test sets, making it easier to bootstrap your evaluation data from production. The new feature lets you:
Additional improvements: