Viewing Traces in the Playground and Authentication for Deployed Applications
Viewing traces in the playground:
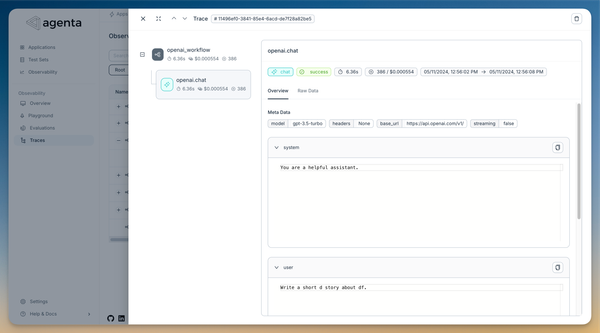
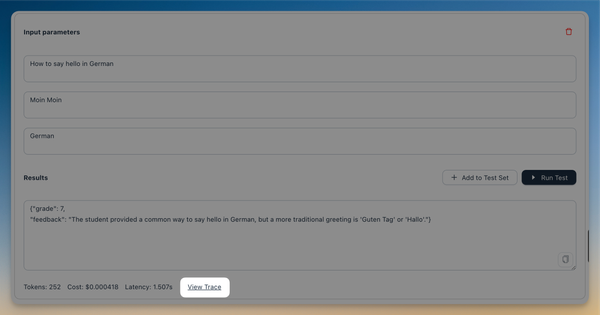
You can now see traces directly in the playground. For simple applications, this means you can view the prompts sent to LLMs. For custom workflows, you get an overview of intermediate steps and outputs. This makes it easier to understand what’s happening under the hood and debug your applications.
Authentication improvements:
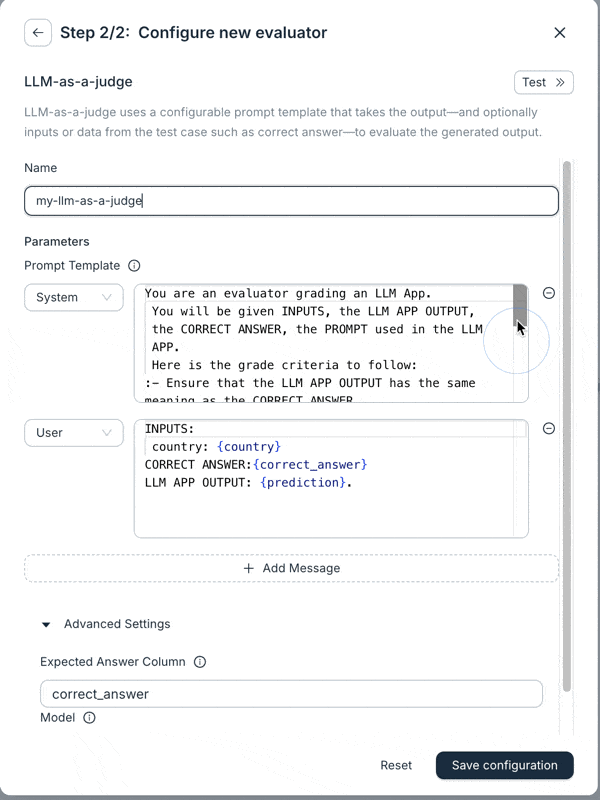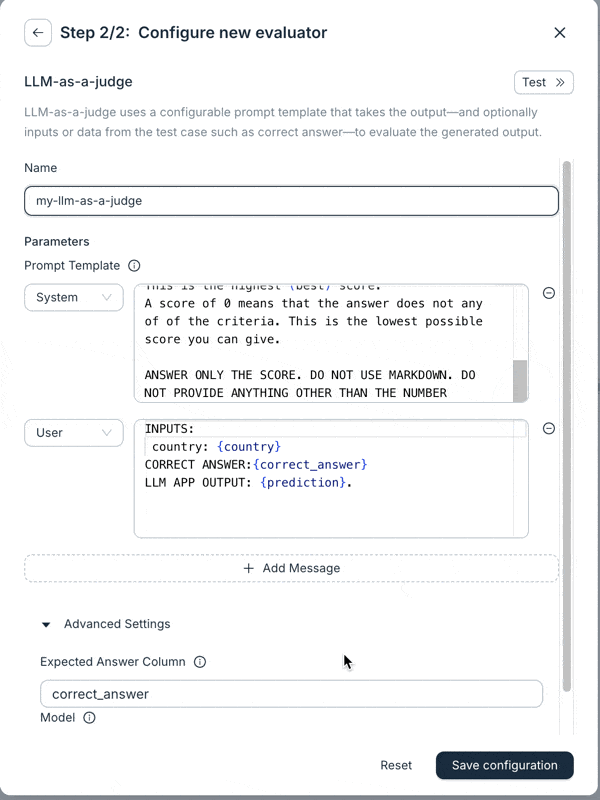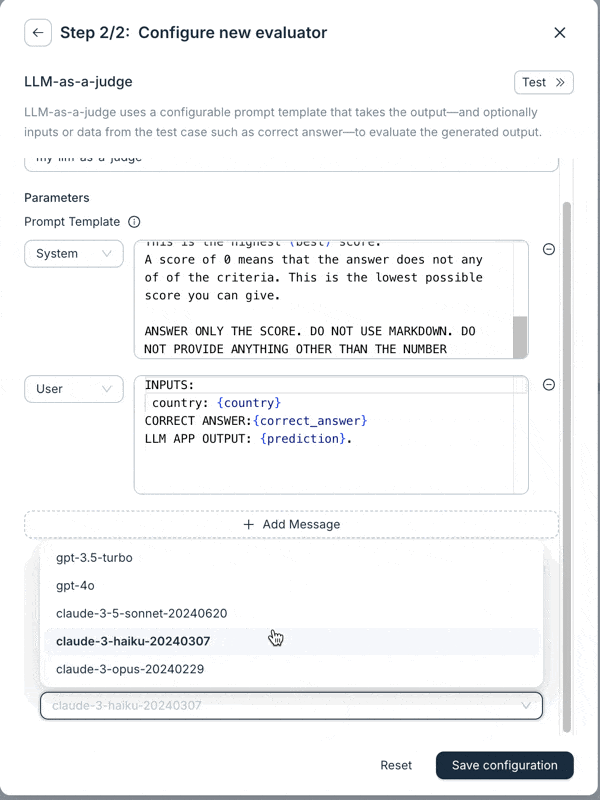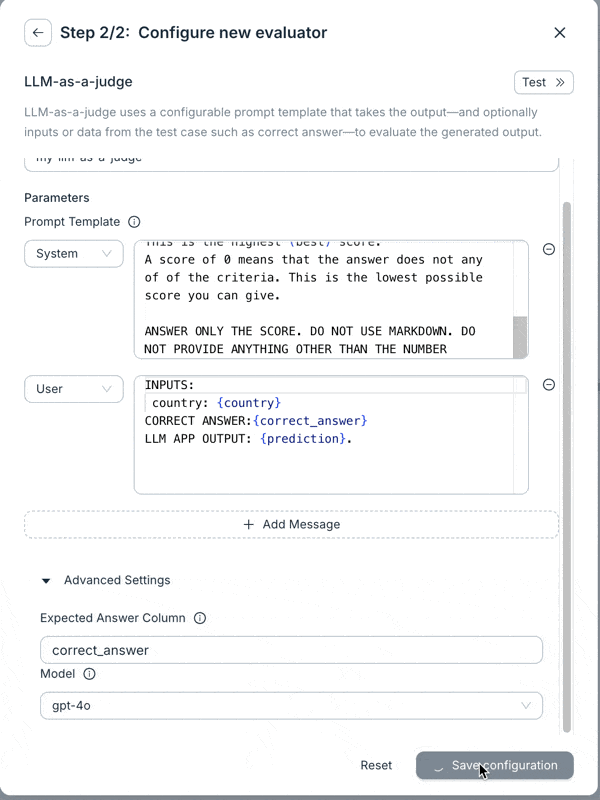
We’ve strengthened authentication for deployed applications. As you know, Agenta lets you either fetch the app’s config or call it with Agenta acting as a proxy. Now, we’ve added authentication to the second method. The APIs we create are now protected and can be called using an API key. You can find code snippets for calling the application in the overview page.
Documentation improvements:
We’ve added new cookbooks and updated existing documentation:
- New cookbook for observability with LangChain
- Updated the custom workflows documentation and added reference
- Updated the reference for the observability SDK and for the prompt management SDK
Bug fixes:
- Fixed an issue with the observability SDK not being compatible with LiteLLM.
- Fixed an issue where cost and token usage were not correctly computed for all calls.